
Cinnamon saw the trend early on, and the team went big. Artificial Intelligence/Machine Learning big. And they brought STRV with them.
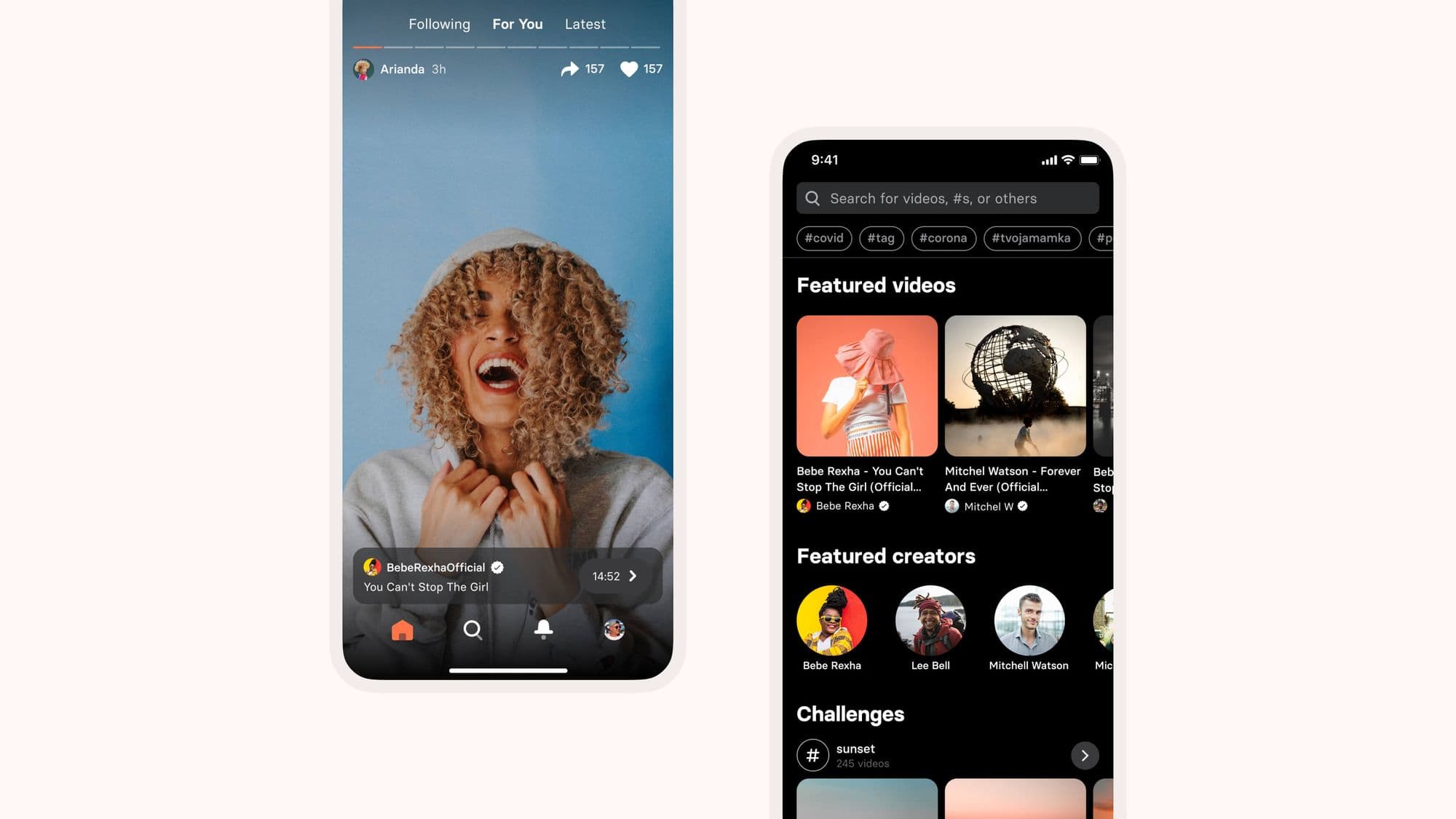
Before we get into our collaboration, a bit about Cinnamon. The enthusiastic, tech-savvy startup built a platform for exploring, creating and sharing video content with no limits. The product includes a unique toolkit for creating video shorts (five to 15-second cuts of content) while providing native cross-app sharing and ad-free monetization.
In early 2020, STRV and Cinnamon linked up. Our team was asked to build iOS and Android mobile apps of a product aiming to be on par with Instagram, TikTok and others. The deadline was four months. Already, a challenge — one that we were happy to take on.
What wasn’t expected and ended up being fundamental to Cinnamon’s success was the Artificial Intelligence (AI)/Machine Learning (ML) aspect of the project. To put it simply, our ML engineer solved the main video recommendation problem, building an AI solution despite a complete lack of relevant user data. He also took an AI model Cinnamon already had and built a new version that was 99% more efficient, 40% more accurate and now exists as a standalone B2B product.
For a less blunt, more expert account of STRV’s collaboration with Cinnamon from the AI/ML perspective, we turned to our Machine Learning Engineer, Jan Maly, who was the sole engineer on the project.
To get the full project story, take a look at our Cinnamon Case Study.


Cinnamon initially approached STRV asking us to build its iOS and Android mobile apps. How did AI/ML come into play, and how were you able to identify opportunities that Cinnamon hadn’t yet pinpointed?
Because STRV has an open community where we share and discuss projects throughout all departments, I came across Cinnamon almost by chance.
The Cinnamon team had previously acquired an emotion recognition solution: AI that evaluates people's reactions when they watch videos by analyzing the expressed emotions. The team had discussed the solution with one of our iOS engineers, and they expressed concerns about the solution’s shortcomings. Namely, that it would be technically challenging and expensive to implement on devices and, more importantly, that the solution itself came with many privacy concerns. They were in a stage of doubt as to whether they would use the AI model at all.
The STRV product manager for Cinnamon approached me to discuss the issue, I analyzed the solution and we debated the use cases. Once I’d received full details of the client’s plans, I came up with a feasible solution for the problem and recommended some relevant value propositions. At this point, it was clear that there was great potential for AI/ML not just in terms of the emotion recognition but also with the video recommendation engine that would give Cinnamon the competitive edge they were looking for.
When we presented all the benefits of our proposed solutions, as well as additional relevant use cases, Cinnamon was instantly on-board.
Can you tell us more about the video recommendation engine, and how it ended up being a fundamental part of the Cinnamon product?
Cinnamon wanted to build a platform with a lot of content and a dominant social aspect. The team was aware that AI/ML plays a vital role in many significant social networks via algorithms that recommend new relevant content and help users find what they want. It’s this capability that makes the big players (like Instagram or TikTok) so successful.
They realized STRV had the skills to deliver something with equally huge potential after our first meeting. They were astonished by the deliverables of our initial solution for emotion recognition, so I guess it was a natural next step to ask us to tackle this second challenge.
You had to work with an exceptionally short deadline of four months, the time Cinnamon had given us to deliver the iOS and Android MVPs, with everything included. How did you manage to make it happen?
With time pressure and huge stakes, you need to develop iteratively and in a way that makes ideas easy to execute and test. Much easier said than done.
I’ll admit it was challenging and quite stressful. ML is all about research, and there is a massive amount of uncertainty. When you think about the success rate of software projects in general, the number of failures is crazy. ML is even worse in this area. You need to have a very specific skillset and unparalleled dedication to be successful.
I had to develop feasible approaches that could be done in a given amount of time, with a reasonable buffer to account for the incredible amount of uncertainty. I spent time researching those approaches, making sure I would choose the absolute best route.
I believe it is essential to prototype and experiment a lot, and to develop solutions iteratively. The goal is to build a simple baseline/solution quickly and improve on this baseline, or try new approaches. With this process, I always have something to show that can be discussed with the client. I make sure to develop modular code and use appropriate tools that allow this sort of development. It’s more about coming up with ideas and executing them quickly.
Going back to the emotion recognition solution, can you explain why you chose to build an entirely new solution rather than tinkering with the one Cinnamon already had?
(Note: Cinnamon chose to separate the emotion recognition solution from the Cinnamon product and offer it as a B2B solution instead. This is due to the sensitivity of user privacy and that such a solution should be in the hands of established, responsible businesses with comprehensive and strict privacy policies.)
The solution Cinnamon had acquired was quite dated. It had old and complex architecture (hardly portable to cheap mobile devices) and used ancient technologies.
The biggest problem was that it was meant to stream video to a backend from the client’s device. This comes with many privacy concerns because a user’s video is sent over the internet. It also has other major drawbacks, like draining data and battery quite quickly.
There were numerous issues with the solution in general. It required running an expensive specialized infrastructure that is difficult to maintain; it was based on dated technologies and architecture that does not allow to export the solution to clients’ devices easily; and it was trained on a biased, central European dataset that is not very representative of the world population.
My goal became to deploy the model on end devices, so inference can be run on the client’s side to resolve major drawbacks. To do this, it was better to start from scratch. Fixing the old model would take unnecessary time and effort. Instead, I used it as a baseline for the new one. It was much better to use new architectures, approaches and technologies, and to improve the dataset itself; the computer vision field has evolved a lot since that first solution was built.
How does the STRV-made emotion recognition model compare to the first one, and what brought it to the next level?
Our model is 99% more efficient and 40% more accurate than the first model. Thanks to the points outlined above, we were able to create exactly what we set out to make.
In summary, it took: New techniques, architecture and approaches; a lot of experimentation; iterative development; an extended dataset; and the utilization of best practices to improve the generalization of the model — data augmentation, regularizations, meta-learning for finding optimal parameters and data cleaning.
You did all of this while building a video recommendation engine, where you had to start with almost zero user data — something that’s incredibly challenging. Can you tell us about the process of making this solution?
That is correct. As a new product, Cinnamon had almost no data on users’ interactions. Therefore, for this phase, we needed to use a highly creative approach to the problem. We decided to build a solution that works with video content rather than with users’ interactions. It is much easier to put together a relevant dataset representing content available on such a platform than to put together a dataset of users’ preferences regarding such content.
I trained a model that can tell similarity between videos based on the content of videos; what kind of activities are happening there and what kind of entities are present. To train the ML algorithm, I sourced a large scale dataset of relevant human-annotated videos. Textual descriptions are then used as the primary measure of similarities between videos — a deep recurrent neural network with a pre-trained image feature extractor is then trained to match the similarity measure properties but for video inputs only. For production, video annotations are no longer required. This approach works surprisingly well.
This model can be used for search right away and it can also be adapted to our use-case: recommendations. To begin with, we used some expert rules on top of the model; once more user interactions are available, we can use another ML model to learn those as well.
Another challenge was the serverless deployment of the ML solution. But, as with everything else — it’s possible. It just takes finding the right angle.
During these jam-packed four months, what did the cooperation with Cinnamon look like?
The Cinnamon team are technological enthusiasts, so we got along very well. They’re constantly open to new ideas, and it was fun to work on AI integration with them. I learned about a few new, cool technologies that they use, and we were able to successfully integrate the video engine AI model with no issue. I honestly really enjoyed the cooperation, from start to finish.



